
Gleiche Inhalte, die über mehrere URLs erreichbar sind – für Website-Betreiber:innen ist Duplicate Content ein großes Problem. Warum? Die Antwort auf diese Frage ist simpel, denn eines stellt Google immer wieder klar: Einzigartiger und mehrwertiger Content ist für die Suchmaschine das A und O, um User:innen die bestmögliche Nutzungserfahrung zu bieten. Duplikate sind diesbezüglich hinderlich und können negative Auswirkungen auf die SEO-Performance der betreffenden Seiten haben. Aus diesem Grund geben wir Hinweise und Tipps, wie man Duplicate Content vermeiden und beheben kann.
Was ist Duplicate Content?
Duplicate Content bedeutet auf Deutsch doppelter bzw. duplizierter Inhalt. Damit bezeichnet man identische Inhalte in derselben Sprache, die mehrfach auf derselben oder einer anderen Domain auftreten. Nicht immer müssen diese Inhalte auch tatsächlich komplett identisch sein – Content-Blöcke mit sehr großer Ähnlichkeit können von Suchmaschinen ebenfalls als duplizierte Inhalte gewertet werden. In diesem Fall spricht man auch von Near Duplicate Content. Diese Duplikate entstehen teilweise unbewusst, manchmal aber auch durch bewusste Handlungen mit einer Täuschungsabsicht und dem Ziel, bessere Rankings in den Suchergebnissen zu erzielen.
Es gibt verschiedene Arten von Duplicate Content: Man spricht von internem Duplicate Content, wenn dieselben Inhalte auf verschiedenen Seiten innerhalb einer Domain zu finden sind, und von externem Duplicate Content, wenn derselbe Inhalt (rechtmäßig oder unrechtmäßig) auf verschiedenen Domains auftaucht. Ob intern oder extern auftretende, unbewusst oder absichtlich verursachte Duplikate: Die Folge sind Beeinträchtigungen der SEO-Performance der betreffenden URLs bzw. Domains. Warum Duplicate Content zu schlechteren Rankings führen kann und einzigartige Inhalte so wichtig sind, erklären wir nachfolgend.
Die Bedeutung von Duplicate und Unique Content
Werden identische Inhalte auf mehreren Seiten veröffentlicht, kann das weitreichende negative Folgen haben. Duplicate Content beeinträchtigt die Performance und Rankings einer Website, da Suchmaschinen wie Google ausschließlich Inhalte mit hoher Qualität und Relevanz für die Nutzenden bereitstellen möchten und diese priorisieren. Tauchen dieselben Inhalte auf mehreren URLs oder Domains auf, fällt es der Suchmaschine schwer, die Relevanz der entsprechenden Seiten richtig einzuordnen und zu bewerten. Der Google-Bot erkennt nicht, welche Seite für die Suchanfrage am relevantesten ist und in den Suchergebnissen erscheinen soll.
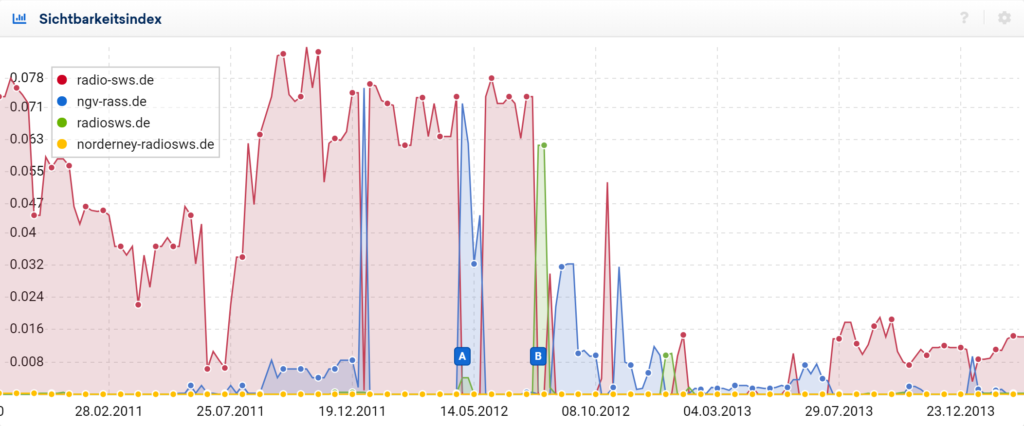
Abb. 1: Vier Domains mit den gleichen Inhalten: Die schwankenden Sichtbarkeitsverläufe zeigen, dass Google Probleme bei der Bewertung der Relevanz der Domains hat und diese deshalb abwechselnd in den SERPs ausspielt. (Quelle: https://www.sistrix.de/frag-sistrix/onpage/duplicate-content/)
Welche Konsequenzen sind in solchen Fällen zu erwarten? Websites mit Duplicate Content haben mit Ranking-Schwankungen und abfallenden Platzierungen in den SERPs zu rechnen, was in einer verminderten Sichtbarkeit und Reichweite der Website resultiert. Google betont jedoch, dass Websites aufgrund von Duplicate Content nicht abgestraft werden. Besteht allerdings die Vermutung, dass Website-Betreiber:innen mit duplizierten Inhalten manipulative Absichten verfolgen, ist mit Abstrafungen zu rechnen. Index und Ranking der betroffenen Websites werden korrigiert. Das kann auch dazu führen, dass die Seiten komplett aus dem Google-Index entfernt werden und somit nicht mehr in den Suchergebnissen erscheinen.
Wie die meisten wissen, zählen einzigartige und mehrwertige Inhalte für Google nicht erst seit dem Helpful Content Update zu den wichtigsten Faktoren für eine erfolgreiche Website. Unique Content ist ein essenzieller Teil der Suchmaschinenoptimierung und entscheidend für gute Website-Rankings: Einzigartige Inhalte tragen dazu bei, dass die Website für Suchmaschinen und Nutzer:innen relevant und wertvoll ist. Ist der Seiten-Content auf die Bedürfnisse und Interessen der Zielgruppe zugeschnitten, verbessern sich nicht nur die Interaktionen und die Verweildauer auf der Website, sondern auch die Chancen auf Backlinks. Mit einzigartigem Content fördert man zudem die Autorität und Glaubwürdigkeit der Seite, was ebenfalls zu besseren Platzierungen in den Suchergebnissen führt.
Um die Wichtigkeit einzigartiger Inhalte noch einmal herauszustellen, haben wir in der nachfolgenden Tabelle zusammengefasst, vor welche Probleme Duplicate Content Suchmaschinen und Website-Betreiber:innen stellt.

Abb. 2: Die Bedeutung von Duplicate Content für Suchmaschinen und Website-Betreiber:innen.
Ursachen für die Entstehung von Content-Duplikaten
Die Ursachen für die Entstehung von Duplicate Content sind vielfältig. Gründe dafür können zum einen technischen Ursprungs sein, aber auch auf inhaltlicher Ebene auftreten. Dies sind nur einige mögliche Ursachen für die Entstehung von doppelten Inhalten:
- Kanonisierungsprobleme treten auf, wenn mehrere URLs dieselben oder sehr ähnliche Inhalte haben, jedoch nicht korrekt auf eine kanonische URL verweisen. Das ist oft bei Parameter-URLs wie etwa Such- oder Filterseiten der Fall. Beim Anwenden von Filtern auf einer Shop-Seite können beispielsweise unterschiedliche URLs mit denselben Inhalten wie „https://shop.de/schuhe/herrenschuhe.html?farbe=weiss&groesse=43&material=leder“ und „https://shop.de/schuhe/herrenschuhe.html?farbe=weiss&material=leder&groesse=43“ entstehen. Per Canonical-Tag teilt man der Suchmaschine mit, dass es sich bei einer bestimmten URL um die Hauptversion einer Seite handelt. Damit wird signalisiert, dass nur diese in den Suchergebnissen ranken soll.
- Viele Seiten mit ähnlichen Inhalten können Probleme mit Near Duplicate Content verursachen und zu Keyword-Kannibalisierungen führen. Eine klare Seitenstruktur hilft, dem entgegenzuwirken, und schafft zudem eine übersichtlichere Nutzungsoberfläche für Website-User:innen.
- Mit Cookies und URI-Attributen, die als Session-IDs an URLs angefügt werden, lässt sich das Verhalten von Website-Besucher:innen analysieren – beispielsweise um festzustellen, welche Produkte im Warenkorb gelandet sind. Dabei entstehen allerdings auch mehrere Versionen einer Seite, zum Beispiel: „https://www.shop.de/seite1“ und „https://www.shop.de/seite1?sessionid=123456“.
- Die Internationalisierung der Website kann durch fehlende hreflang-Attribute bei Länderdomains mit weitestgehend identischen Inhalten und nur geringen sprachlichen Abweichungen (zum Beispiel im deutschsprachigen Raum: Deutschland, Österreich und Teile der Schweiz) zu Duplicate-Content-Problemen führen. Durch das hreflang-Attribut erhält der Google-Bot Informationen über die Seitenarchitektur einer internationalisierten Website, erkennt verschiedene Sprachversionen und spielt diese an die richtigen Zielgruppen aus.
- Wird beim Umziehen einer Domain für die alte URL keine Weiterleitung auf die neue URL eingerichtet, sind zusätzlich zu den neuen Seiten auch noch sämtliche Seiten der alten Domain mit denselben Inhalten erreichbar und indexiert. Dies stellt jedoch nur ein Problem dar, wenn die alte Domain aktiv bleibt und die URLs auf „index,follow“ gesetzt sind.
- Legt man eine Kopie der eigenen Website für das Testen neuer Design-Elemente, Programmierungen oder Ähnliches an, haben Suchmaschinen ebenfalls Zugriff auf diese Domain, falls diese nicht über die .htaccess-Datei mit einem Passwort geschützt oder der Zugriff für Web-Crawler per robots.txt verwehrt wird.
- Das Bereitstellen von Print-Versionen einer Seite (z. B. als PDF-Datei oder als separate printfähige Seite) kann von der Suchmaschine als duplizierter Inhalt gewertet werden.
Duplicate Content erkennen, beheben und vermeiden
Bei der Onpage-Optimierung kommt es nicht nur darauf an, Duplicate Content zu vermeiden, sondern diesen im Ernstfall auch schnellstmöglich zu erkennen und zu beheben. SEO-Tools wie Google Search Console, Screaming Frog, SEMrush, Sistrix oder Seobility bieten Features für den Duplicate-Content-Check und helfen bei der Identifizierung ähnlicher Inhalte. Sie zeigen, ob es sich um doppelten Content auf der eigenen oder einer anderen Domain handelt, und weisen betroffene URLs aus.
Wird Duplicate Content erkannt, sollten Website-Betreiber:innen schnell handeln, um Ranking-Verlusten, Abstrafungen oder Indexierungsproblemen und -ausschlüssen entgegenzuwirken. Um Probleme mit Duplicate Content- zu vermeiden und sicherzustellen, dass User:innen die gewünschten Inhalte finden, sind verschiedene Maßnahmen möglich. Zu den Best Practices zählen:
- einzigartigen Content erstellen und Texte für verschiedene Bereiche individualisieren, beispielsweise für die Nutzung auf der eigenen Website, externen Preisvergleichsseiten oder Shopping-Portalen
- Seiten mit ähnlichen Inhalten reduzieren, indem einzelne Seiten mit individuellem Content erweitert oder mehrere Seiten zu einer Einzigen zusammengefasst werden
- durch einen Canonical-Tag im Quellcode der duplizierten Seite auf die Hauptseite verweisen, sodass das Duplikat bei der Indexierung nicht berücksichtigt wird
- Seiten mit Duplicate Content mit dem noindex-Tag markieren, damit eine Indexierung gar nicht erst erfolgt
- wiederkehrende Textbausteine reduzieren und stattdessen zum Beispiel auf eine separate Seite mit ausführlichen Informationen zu dem Thema verlinken
- bei Umstrukturierungen der Website 301-Weiterleitungen für Seiten einrichten, die nicht in den Suchergebnissen erscheinen sollen
- dieselben Links für interne Verlinkungen verwenden und Linkvariationen wie „http://www.beispiel.com/seite/“, „http://www.beispiel.com/seite“ und „http://www.beispiel.com/seite/index.htm“ oder unterschiedliche Groß- und Kleinschreibung in Links vermeiden
- bei internationalisierten Seiten das hreflang-Attribut verwenden, damit der Google-Bot Inhalte auf einzelnen Länderdomains mit identischer bzw. sehr ähnlicher Sprache nicht als doppelten Content einstuft
In den Google-Guidelines zum Vermeiden von Duplicate Content werden diese Maßnahmen und Handlungsempfehlungen explizit genannt. Darin heißt es auch, dass man Crawler-Zugriffe auf Duplicate-Content-Seiten nicht blockieren sollte. Denn wird der Zugriff verweigert, behandelt der Crawler die Seiten separat, da er nicht automatisch erkennen kann, dass die URLs auf gleiche Inhalte verweisen. Es wird empfohlen, eine URL-Kennzeichnung als Duplikat – durch die Nutzung des Link-Elements rel=“canonical“ oder einer 301-Weiterleitung – vorzunehmen und das Crawlen dieser URLs zu erlauben.
Was tun, wenn Seiten wegen duplizierter Inhalte aus den SERPs entfernt wurden?
Wenn eine Website aus den Suchergebnissen aufgrund eines Täuschungsversuchs entfernt wurde, sollte die Website geprüft werden. Erst nach einer den „Richtlinien für Webmaster“ entsprechenden Überarbeitung sollte eine erneute Überprüfung der Seite bei Google beantragt werden.
Wählt der Google-Algorithmus die URL einer externen Website, die Inhalte ohne die Zustimmung der Urheber:innen wiedergibt und damit das Urheberrecht verletzt, sollte man zunächst die Seiten-Betreiber:innen mit der Bitte kontaktieren, auf die Originalquelle zu verweisen oder die Inhalte zu entfernen. Kommt der Website-Host der Aufforderung nicht nach, bietet die Google Search Console ein Formular zur Kontaktaufnahme, um Seiten mit rechtswidrig verwendeten Inhalten aus den Suchergebnissen entfernen zu lassen.
Fazit
Auch wenn bei unbewusst erzeugtem Duplicate Content in der Regel nicht mit einer Abstrafung durch Google zu rechnen ist, können duplizierte Inhalte der betroffenen Website schaden und beispielsweise Indexierungsprobleme verursachen oder zu Ranking-Verlusten führen. Als eine der effektivsten Maßnahmen zum Schutz vor Duplicate Content gilt das Erstellen einzigartiger Inhalte – die ganz nebenbei auch noch das Image und die Glaubwürdigkeit der eigenen Marke stärken. Doch auch ein kontinuierliches SEO-Performance-Monitoring der eigenen Website ist unerlässlich: Hält man die Werte stets im Blick und prüft regelmäßig den Indexierungsstatus, lässt sich Duplicate Content schnell erkennen und beheben.

Marika Tauche



